
简介
llvm-obfuscate 我习惯叫成ollvm。
我也不知道怎么介绍,自己去看呗。https://github.com/obfuscator-llvm/obfuscator.git
搭建方法
ollvm git地址:https://github.com/obfuscator-llvm/obfuscator.git
ollvm 的编译需要使用cmake ,g++,因此需要先装有对应的环境
编译ollvm
make -j4表示为使用4个编译器同时进行编译,可以有效地提高编译的效率。可以根据CPU的核数进行一定程度的修改。
编译完成后,程序都在build/bin和build/lib之中
用于测试的代码
linux 下的使用方法
可以将ollvm理解成一个编译器,使用方法很简单。
obfuscator-llvm-3.4/build/bin/clang xx.c –o xx -mllvm -fla
效果如下,正常没有使用ollvm的逻辑图: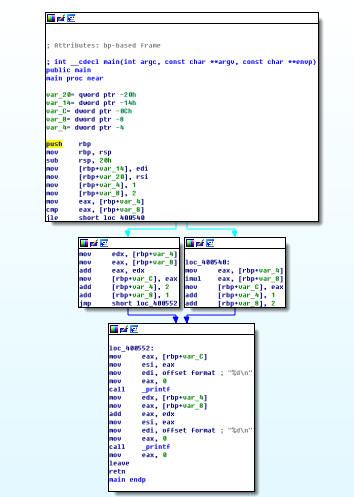
简单使用ollvm后: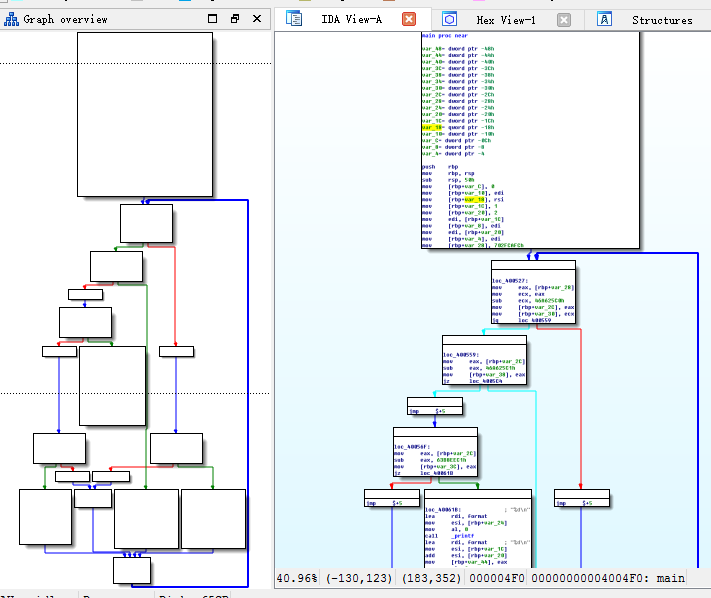
简单使用ollvm后的伪代码:

结合Android ndk的使用方法
暂略,原理是与ndk结合进行编译,以后补充。
ollvm常用的参数
指令替代 -mllvm -sub
控制流程伪造 -mllvm -bcf
控制流平坦克 -mllvm -fla
命令结构入戏
-mllvm -bcf
-mllvm -perBCF=20: 对所有函数都混淆的概率是20%,默认100%
-mllvm -boguscf-loop=3: 对函数做3次混淆,默认1次
-mllvm -boguscf-prob=40: 代码块被混淆的概率是40%,默认30%
BCF(Bogus Control Flow)模式
BCF中文名叫控制流伪造模式,从名字就可以理解大概了。BCF模式会在代码前后随机插入代码块,而原代码块也可能会被克隆,然后随机插入垃圾指令。
对抗方式
控制流平坦化
个人对控制流平坦化的理解,其实就是通过给程序增添一个控制器,并且根据预定或者是在运行中修改的参考值来对程序的整个流程进行控制。使得从流程图上看,程序增添了各种的分支,但事实上程序的流程仍和原本流程的一样。
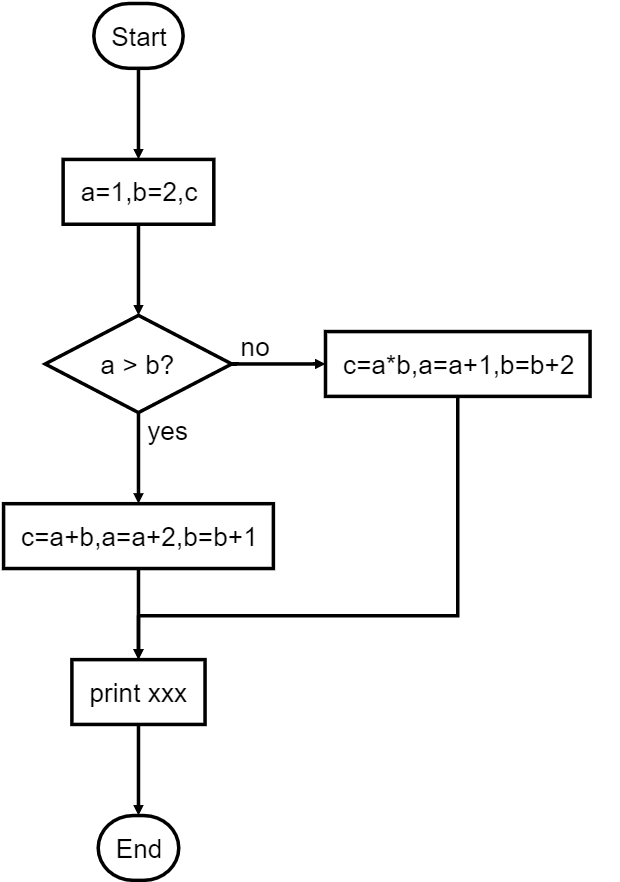
用流程图表示应该如下吧:
原始的流程:
控制流平坦化后,ida转化出来的伪代码如下:
流程图可以理解成如下: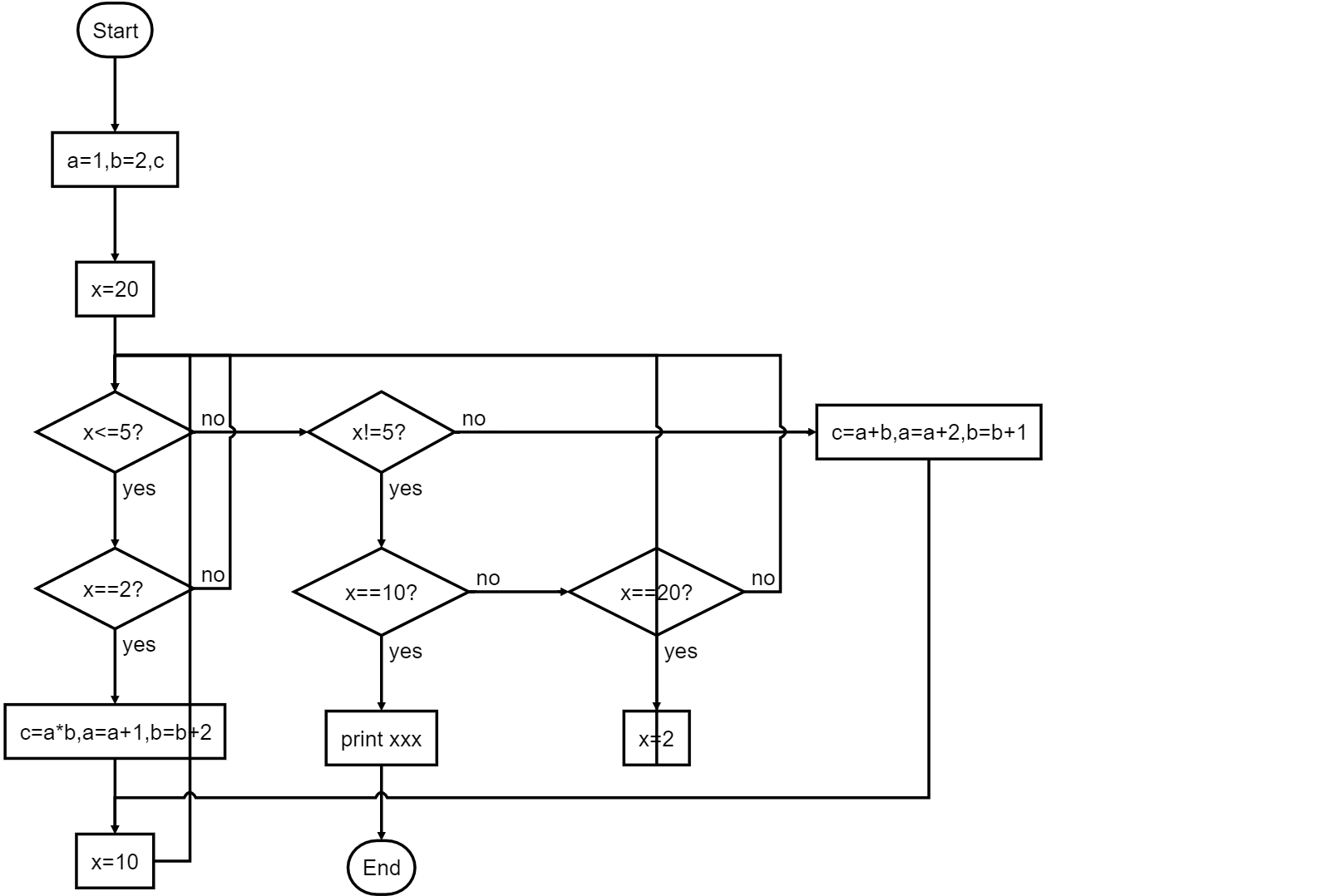
厄~这图虽然复杂,但应该没错了的,应该吧…..但可以看到确实复杂了很多。
初步理解了之后,然后就可以看下TSRC博客中的文章了。《利用符号执行去除控制流平坦化》或者国外的提出该思想的文章《Deobfuscation: recovering an OLLVM-protected program》
该文章的基本思想,就是通过分析程序的CFG图片,统计出一些规律。然后根据规律对混淆过的文件进行patch进行修改。
大概的规律如下:
根据我自己的实验,根据上面那几点来进行还原,确实是能够将程序还原得跟源程序十分相近,但却还是有所不同的。
|
|
这里可以看出,根据规则识别,得到的是3个主块,相比原来的正确逻辑是多了一个主块的。
唉~…..未完待续吧,算是理解了,但不知道怎么写下去了。